All virtualization technologies provide an environment in which one or more virtual computers (guests) run within a single physical computer (host).
This is achieved with a virtualization layer, in some cases known as a hypervisor. The virtualization layer provides each guest with an environment that emulates a physical computer, and manages resources (CPU, memory, IO) across the guests.
Virtualization layers tend to fall into one of three models: hosted hypervisor; operating system; or native hypervisor.
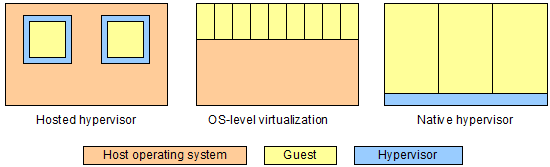
- A hosted hypervisor is a software application that runs within the host's operating system.
- Operating system-level (OS-level) virtualization is provided by a specialised operating system without a separate hypervisor layer.
- A native hypervisor (or bare-metal hypervisor) sits below the guest operating system and controls the virtualization.
These different models have a big impact on the performance of the guests, what guests can be run, how well the guests are isolated from each other, and how many guests can be packed onto a single host.
In the hosted hypervisor approach, guests run as applications on the host. The guests will tend to compete with each other for physical resources such as CPU and memory. The virtualization layer can typically emulate a variety of physical devices, and can support a wide variety of guests. The reliance on emulation, and the number of layers involved, tends to reduce performance. Because each physical computer needs a complete copy of the operating system, relatively few guests can be supported by each host.
OS-level virtualization overcomes many of the shortfalls of hosted hypervisors. The host operating system understands virtualization, and shares out resources effectively. The host operating system may provide common device drivers, a common kernel, and even common parts of the file system, which can be used by the guests with very little overhead. OS-level virtualization tends to be fast, and allows many guests to be packed onto a host. On the downside, the guests all have to run an operating system compatible with the host, and the performance of each guest can be heavily affected by the other guests.
The native hypervisor approach is different again. It provides a virtual environment that is close to a physical environment, with good partitioning of resources and allowing a variety of operating systems to be used. It is not as good at packing in guests as OS-level virtualization, because the virtual computers are more separated and share less. It provides good isolation between guests.
There is no right or wrong approach. Different virtualization technologies meet different needs.
Hosted hypervisors are relatively simple, and make it easy to setup a guest on any server or PC. They are good for creating test environments, or for running an old operating system version for a legacy application.
OS-level virtualization is good for creating similar guests at very low cost. It is used heavily by providers of web hosting.
Native hypervisors are good for mixed production use, because they provide more predictable performance and good isolation.
To illustrate these different approaches, next week I will look more closely at examples of each.
© Copyright 2009 Minimal IT Ltd. See the Minimal IT website for the original newsletter and copyright information.