Taking a different approach to development can reduce the need for testing.
I am a great believer in test-driven development. The value proposition is clear: it is simpler, quicker and cheaper to create tests before you write code than to debug and fix code after you have written it.I now develop a lot of solutions using our Metrici Advisor software. Developing in Metrici Advisor is radically different from a traditional software development environment. Because of this, we have to rethink how to approach development tasks, in particular testing.
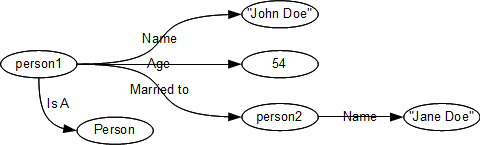
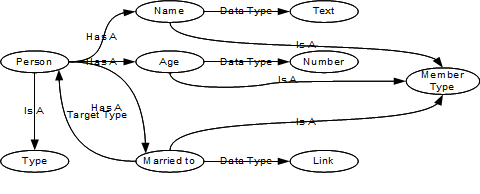
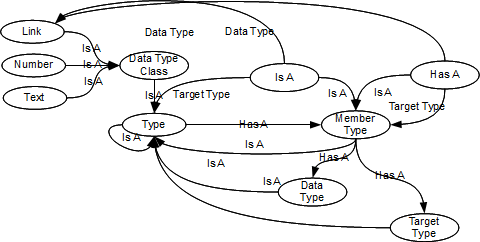
There are two aspects of Metrici Advisor which challenge my views on testing:- There is not much to test in Metrici Advisor. The solution is defined in metadata, and once the definition is correct the solution functions correctly. The only thing to test in a conventional sense are the little snippets of JavaScript that provide calculations, and there are very few of these.
- The development speed of Metrici Advisor gives us new opportunities. We can create solutions in a few hours, and to make the most of this we build early versions of solutions as part of the sales process. These evolve into the final solutions, without ever having gone through a formal development process.
We are finding that development in Metrici Advisor is more like creating content. Early drafts are usable, and we can refine the solution gradually as a result of feedback.
Continually making changes to a solution could make it unstable. In conventional systems, components are linked together by reading code from files with specific names. Because components are only linked by file names, changing a component will impact all other components that reference it. In Metrici Advisor, components are versioned and are explicitly linked to specific versions of other components. New versions can be created without impacting existing versions.This provides a very stable, forgiving environment. We can create an early draft, and try it out. Then we can create revisions to it, and try those out, without disrupting the earlier versions. Even after a solution has gone live, we can change it without impacting existing users, and upgrade existing users to the new versions when they are stable.
We are still trying to understand what disciplines we need for developing in Metrici Advisor. We probably do need a more formal proving and validation process as solutions move forward from the early draft stage. However, the mixture of metadata-based development and version management significantly reduces the cost and impact of change, which completely changes the value proposition of testing. Perhaps now we can test less, and test later.© Copyright 2012 Minimal IT Ltd. See the Minimal IT website for the original newsletter and copyright information.